Regex for lazy developers
26 апреля 2022
Наш Team Lead, Илья Ермошин, делится с вами интересной и полезной информацией о регулярных выражениях. Все, что вы не знали и боялись спросить! ;)
Основы. Что такое Regex?
Регулярные выражения – это система обработки текста, основанная на специальной системе записи образцов. Она дает программистам возможность легко обрабатывать и валидировать строки. Представляет имплементацию принципа DRY (Don’t Repeat Yourself), почти во всех поддерживаемых языках паттерн регулярных выражений не будет изменяться. Код, написанный на backend и frontend приложениях, будет идентичным, позволяя экономить время командам на реализацию одинаковых фич. Также стоит обратить внимание на то, что данный модуль идеально подходит для работы с большими строками или сложными строками, так даёт возможность решать задачи связанные с ними просто и быстро.
Как это выглядит?

Первая особенность Regex модуля — паттерн условия будет полностью идентичным.
Вы можете легко поделится своим кодом с командой, которая пишет на другом языке программирования. Возможность быстро "шарить" кодовую базу между разными командами позволяет экономить время на разработку и реализацию фич.
Как появились Regex?
Впервые регулярные выражения возникли в научных работах по теории автоматов и теории формальных языков в середине 1950-х. Стефан Коул Клин признан человеком, который впервые ввёл понятие Регулярных Выражений.
Принципы и идеи, заложенные в его работах, были практически реализованы Кеном Томпсоном и с его лёгкой руки проникли в язык Perl.
Регулярные выражения – это модуль вашего языка программирования, который используются для поиска и обработки текста.
Язык Regex не является полноценным языком программирования, хотя, как и другие языки, имеет свой синтаксис и команды.
Какие языки программирования поддерживают Regex?
Список довольно обширный вот лишь несколько из них:
C, C#, C++, Cobol, Delphi, F#, Go, Groovy, Haskell, Java, JavaScript, Julia, Kotlin, MATLAB, Objective-C, PHP, Perl, Python, R, Ruby, Rust, Scala, Swift, Visual Basic, Visual Basic .NET
Возможности регулярных выражений
- Сопоставление входных данных по шаблону.
- Поиск и изменение входных данных по шаблону.
- Возвращение первого или всех результатов из входной строки.
- Возвращение вместе с результатом общего поиска, именованные и не только подстроки при поиске.
- Замена символов, слов, фраз в входной строке после прохода.
- И самое главное, пиши один раз и используй везде.
Где пригодятся Regex?
- Поиск и замена кода по паттерну в IDE (VS Code, Rider, CLion, VS)
- Валидация строк на соответствие шаблону (file extension).
- Валидация полей на фронте (e-mail, phone number and other).
- Валидация request и response данных.
- Валидация огромных строк с последующим получением необходимых кусков текста без больших затрат по времени.
Базовый синтаксис
- ^ – начало строки (означает, что входная строка должна начинаться с последующего символа после этого. Не подходит, если вы не знаете первый символ входной строки)
- $ – окончания строки (означает, что все условия до этого символа буду являться конечным результатом входной строки и после них ничего дальше нет. Не подходит, если вы хотите вернуть несколько результатов из входной строки)
- * – означает, что предыдущее условие до данного символа может встречаться один или несколько раз или вовсе не будет (соответственно может повторятся)
- + – означает, что предыдущее условие до данного символа должно встречаться один и более раз (соответственно, может повторятся)
- [a-z] – перечисление допустимого символа в входной строке, то есть может быть любой буквой из латыни в нижнем регистре (a or b or c … or x or y or z)
- [0-9] – перечисление допустимого символа в входной строке, то есть может быть любой буквой из латыни в нижнем регистре (1 or 2 or 3 … or 7 or 8 or 9)
- . – один любой символ
- \ – экранирование любого спец. символа
- | – операция OR (означает, что должно выполнится условие слева или условия справа от этой операнды)
Упрощение синтаксиса
- \d ≡ [0-9] – любой символ от 0 до 9
- \D ≡ [^0-9] – любой символ, кроме чисел
- \w ≡ [a-zA-Z0-9_] – любой символ латыни, все числа и _
- \W ≡ [^a-zA-Z0-9_] – любой символ, кроме латинских символов, чисел и _
- \s ≡ [ ] – исключительно пробел
- \S ≡ [^ ] – любой символ, кроме пробела
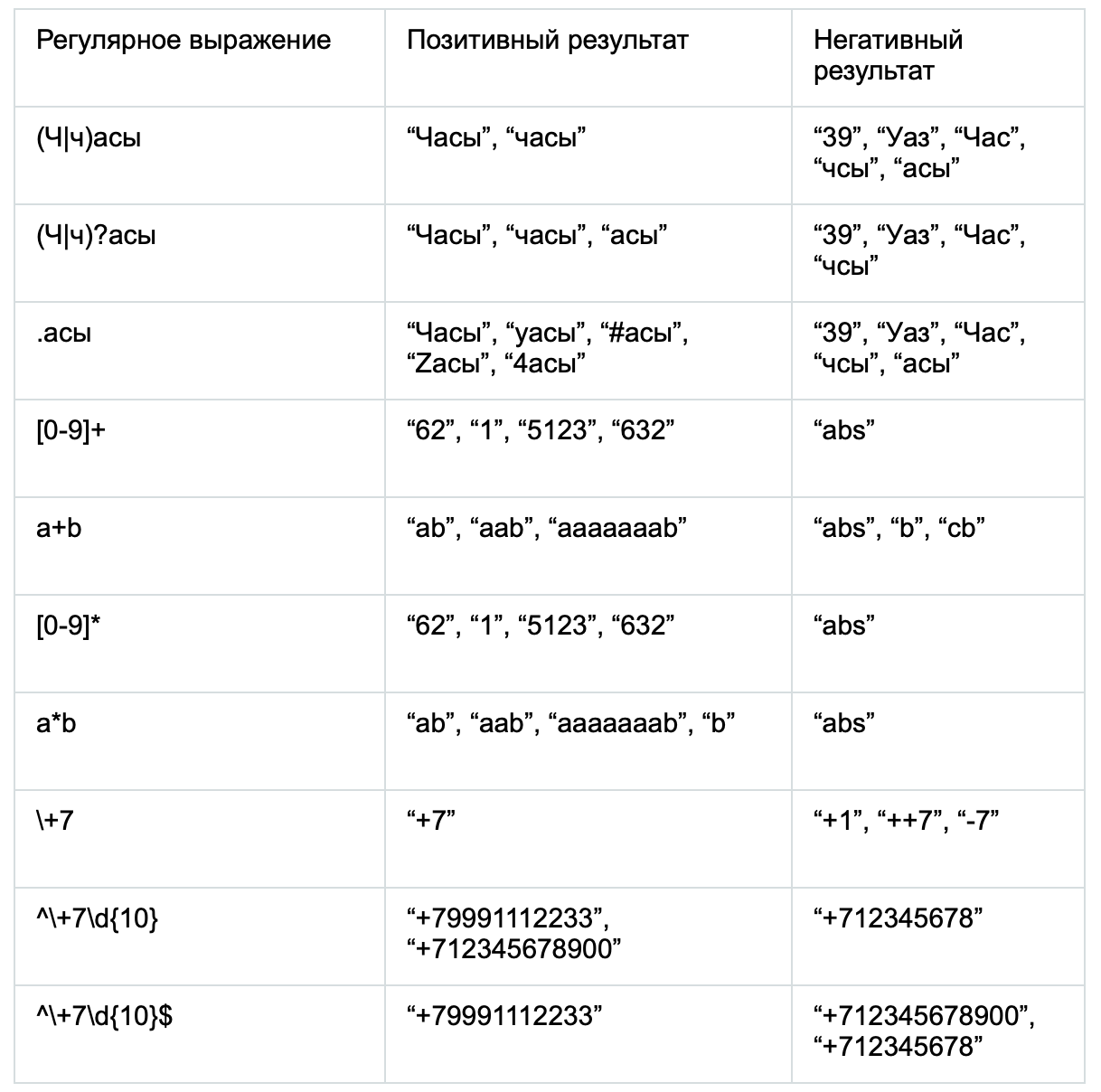
Кроме валидации значений в строке мы также можем указывать, сколько символов должно проходить одно и тоже условие. Есть всего три возможности работать длиной условий:
- {3} – обязательное кол-во символов для условия
- {3,5} – мин. и макс. кол-во символов для условия
- {3,} – обязательное мин. кол-во и неограниченное макс. кол-во

Условие “[0-9]” можно заменить на сокращение “\d”
Проблема работы с не латынью
Когда вам необходимо работать со всем алфавитом из латыни, достаточно просто написать [a-zA-Z]. Многие подумают, что при работе с кириллицей хватает написать [а-яА-Я]. Вроде всё логично и всё хорошо, но в какой-то момент вы поймете, что у вас иногда она работает некорректно.
Проблема заключается в том, что диапазон [а-я] не включает в себя букву “ё”, соответственно, вам необходимо изменить ваш паттерн с [а-яА-Я] на [а-яёА-ЯË], чтобы код учитывал специфичную букву в алфавите. Такая проблема есть не только в кириллице, также эта проблема актуальна для греческого, турецкого и ряда других языков. Будьте внимательны при написание паттерна, который должен использовать эти языки.
Флаги regex в JS
- global (g) - не прекращает поиск после нахождения первого соответствия.
- multi line (m) - ищет по строке включая перенос строки (^ начало строки, $ конец строки).
- insensitive (i) - производить поиск вне зависимости от регистра (a ≡ A)
- sticky (y) - поиск возвращает, кроме совпадения индекс с начала совпадения подвыборки (не поддерживается в IE)
- unicode (u) - поиск включает unicode символы (не поддерживается в IE)
- single line (s) - в этом режиме символ “.” включает в себя также перенос на новую строку (поддерживается в Chrome, Opera, Safari)
Дополнительные настройки regex в C#
RegexOptions выставляется как дополнительный параметр в конструкторе Regex класса. Также его можно указывать в методах Match, Matches.
- None - выставляется по дефолту.
- IgnoreCase (\i) - проверяет без учёта регистра.
- Multiline (\m) - работа со строкой где есть переносы \n.
- ExplicitCapture (\n) - добавляет в результат только именованные группы.
- Compiled (будет полезен лишь в static варианте, ускоряет регулярку, замедляет компиляцию).
- Singleline (знак “.” будет обозначать любой символ кроме \n и игнорирует его при поиске)
- IgnorePatternWhitespace (\x) . (вырезает все пробелы, исключения в конструкциях[],{})
- RightToLeft - поиск справа налево.
- ECMAScript (JS like версия, но стиль группировки как в .NET).
- CultureInvariant (сравнивает игнорирую раскладку клавиатуры).
Хорошие практики и советы по оптимизации
- Чем меньше группировок, тем быстрее скорость выполнения. Cтарайтесь их избегать, если они вам не нужны.
- Используя сокращения (\d, \w и другие), будьте уверены, что они полностью соответствуют вашим условиям поиска.
- Если вы часто используете регулярные выражения, создайте его один раз глобально, тем самым снизив кол-во дубликат кода.
- Почти везде есть возможность компиляции регулярных выражений, которая зачастую оптимизирует ваши выражения и ускоряет их выполнения. Но используйте их после проверки, это ускорит работу вашего кода.
- Старайтесь уменьшить количество экранирования (\), данный функционал замедляет скорость выполнения во многих языках программирования.
- У регулярных выражений есть поддержка utf кода символов. В некоторых моменты это позволит улучшить производительность, но уменьшит читаемость. Если решитесь их использовать, будьте уверены, что команда одобрит ваше решение и оно того стоит.
Регулярные выражения лишь хотят казаться сложными, но на самом деле возможности, которые они предоставляют, дают массу преимуществ и позволяют упростить и ускорить работу всем от Junior-а до Senior/Lead-a.
Программируйте, это классно!
{kind=link}